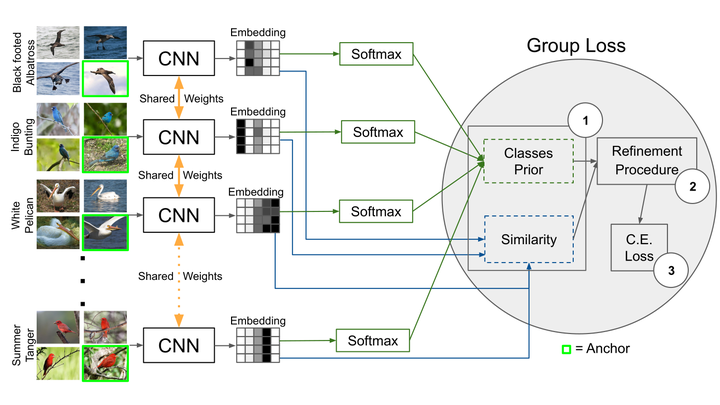
 The pipeline of the method
The pipeline of the method
Abstract
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that “similar objects should belong to the same group”, the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We show state-of-the-art results on clustering and image retrieval on several datasets, and show the potential of our method when combined with other techniques such as ensembles. To facilitate further research, we make available the code and the models at https://github.com/dvl-tum/group_loss
Code available here.